Portada
mis comunidades
otras secciones


#11 Hola. Muchas gracias, la verdad es que aún ando trasteando con la web, se agradece el consejo.
Esta sección es la de artículos, cierto? Entonces publicar los artículos aquí y enlazarlos directamente no sería considerado spam? Gracias por la ayuda!
#28 Hay una web que te hace el trabajo de poner un hilo de twitter más legible, te paso un ejemplo con uno de tus hilos:
https://threadreaderapp.com/thread/1259472794817048577.html
https://threadreaderapp.com/

#28 Exacto. Puedes combinar ambas cosas y hacer un envío "todo en uno" si no te importa el trabajo extra: el artículo completo más el enlace al tuit donde lo publicas, siempre que tú seas el autor.
También puedes publicar en tu Twitter el enlace al artículo en Menéame, para quien prefiera otra método de lectura del artículo.
#37 Gracias!
#9 Hola. La cifra final a la que llega es un claro de ejemplo de fabricación de datos, ya que parte de la hipótesis final y crea el método (muy chapucero, indigno para un doctor usar reglas de tres) para llegar a ese resultado. Esto es un ejemplo perfecto de manipulación y falseamiento de datos.
#21 Ya te he respondido educadamente, pero veo que continúas insistiendo así que lo repito.
He publicado el hilo como enlace y como artículo A LA VEZ, con el esfuerzo que ello conlleva, para dar más facilidades a quien prefiera formato Twitter o formato artículo. No escribo el artículo porque el enlace no tenga "éxito" (no sé a qué te refieres), lo hago A LA VEZ.
#5 Con el agravante de ser profesor de Universidad en la materia y "experto". Cero rigor.
#6 Hola, soy nuevo aquí y quizá desconozco algunas de las reglas internas de la web, disculpas por ello.
He publicado en dos formatos (enlace y artículo) no por duplicar, sino porque entiendo que para algunas personas quizá es más cómodo no salir de la Web y leerlo directamente aquí. Para mí es más cómodo pegar el enlace, adaptarlo al formato artículo es bastante time consuming.
Respecto a lo del texto original, tal como leí en las condiciones de la Web no hay problema con tal de que las contribuciones no queden reducidas únicamente a autopublicidad, es decir, si también comparto noticias de otras fuentes no hay problemas, siempre según los términos y condiciones de Menéame.
No entiendo lo de "como no tiene éxito". Hice los dos formatos a la vez, me importa bien poco el "éxito", solo quiero dar a conocer una mala práctica.
Un saludo.

#23 El artículo está bien... ya estaba publicado en otro artículo en portada: Desmontando las cifras de muertos por covid-19 de un experto en Big Data
El autobombo está permitido de forma ocasional. Tú no has subido nada que no sean tus tweets... es spam.
Cuando digo tener éxito me refiero a llegar a portada. No puedes enviar lo mismo en articulos que en historias... es duplicada.
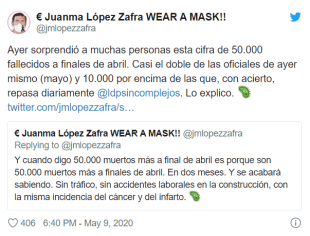
Este artículo fue inicialmente publicado en Twitter en forma de hilo. Se agradece difusión. https://twitter.com/Martinez__Rafa/status/1259472794817048577?s=20Las manipulaciones en RRSS están a la orden del día, y la difusión de bulos crece sin control. Tal es el nivel de desinformación que incluso supuestos "expertos" contribuyen a generar y expandir inexactitudes deliberadamente. Hoy toca hablar de Juan Manuel López Zafra, profesor de Estadística e Investigación Operativa, autodenominado "experto" en Big Data, doctor en Ciencias Empresariales e influencer del liberalismo económico en Twitter.Juan Manuel, durante las últimas semanas, ha presumido de haber calculado con un método propio la cifra aproximada de muertes por Coronavirus en España. Ya el 9 de mayo hablaba de esa cifra. De una persona con el currículum mencionado anteriormente esperaríamos un análisis riguroso, ¿no? Pues bien, lo que verán a continuación les sorprenderá...Juan Manuel afirma que la cifra de muertos a causa del COVID es mucho más alta que la oficial proporcionada por el Ministerio de Sanidad, e incluso bastante superior a los excesos de mortalidad recogidos en los informes MoMo. ¿Cómo ha llegado a esa cifra exacta? Veamos. Juanma parte de una noticia de Europa Press donde se recoge que Mapfre ha prestado 3100 servicios de decesos por COVID. Adicionalmente, Juanma añade que Mapfre en España tiene un 13.7% de cuota, y que el 47% de la población española está cubierta por un seguro de decesos.
De una persona con el currículum mencionado anteriormente esperaríamos un análisis riguroso, ¿no? Pues bien, lo que verán a continuación les sorprenderá...Juan Manuel afirma que la cifra de muertos a causa del COVID es mucho más alta que la oficial proporcionada por el Ministerio de Sanidad, e incluso bastante superior a los excesos de mortalidad recogidos en los informes MoMo. ¿Cómo ha llegado a esa cifra exacta? Veamos. Juanma parte de una noticia de Europa Press donde se recoge que Mapfre ha prestado 3100 servicios de decesos por COVID. Adicionalmente, Juanma añade que Mapfre en España tiene un 13.7% de cuota, y que el 47% de la población española está cubierta por un seguro de decesos. Desconozco la veracidad de esos datos, pero démoslos por buenos, pues son los que Juan Manuel utiliza para su análisis. Bien, la pregunta es, ¿cómo con esos tres datos tan sencillos Juanma es capaz de estimar con precisión el total de decesos por COVID? El método científico de Juanma es... una regla de tres. Si Mapfre con un 13.7% de cuota ha notificado 3100 decesos, eso implica que todas las aseguradoras habrán notificado 3100x100/14=22627 decesos. Si las aseguradoras cubren al 47% de la población, el total será 22627/47x100.
Desconozco la veracidad de esos datos, pero démoslos por buenos, pues son los que Juan Manuel utiliza para su análisis. Bien, la pregunta es, ¿cómo con esos tres datos tan sencillos Juanma es capaz de estimar con precisión el total de decesos por COVID? El método científico de Juanma es... una regla de tres. Si Mapfre con un 13.7% de cuota ha notificado 3100 decesos, eso implica que todas las aseguradoras habrán notificado 3100x100/14=22627 decesos. Si las aseguradoras cubren al 47% de la población, el total será 22627/47x100. Esa operación nos entrega un resultado de 48144, que es la cifra que Juanma utiliza para decir que en España hay aproximadamente 50000 decesos por #COVID19. La pregunta inmediata es, ¿cómo de rigurosa es esa cifra y el método usado? Cualquier persona con mínimas nociones de estadística o matemáticas se habrá dado cuenta que este método hace aguas por todas partes. Una regla de tres a fin de cuentas no deja de ser una interpolación lineal, por tanto se corre el riesgo de que los resultados estén muy sesgados. Utilicemos un ejemplo muy sencillo. Imaginemos que en España un 5% de la población juega a la petanca. Imaginemos que entre los jugadores de petanca hay 5000 muertos por COVID. Según el método de Juanma, si entre el 5% de la población hay 5000 decesos en el 100% de la población habrá 5000x20=100000 decesos. Es evidente que este dato sería erróneo. La población que juega a la petanca suele ser de avanzada edad, por tanto la letalidad asociada al COVID será también mayor en ese grupo. Este error es un claro ejemplo de "sesgo de selección". Como soy nefasto explicando conceptos, dejo aquí este simpático vídeo donde se explica de una manera muy sencilla (a partir del minuto 4:30 aproximadamente, por Julio Basulto).Volviendo al método de Juanma, él parte de los casos de mortalidad notificados por Mapfre por COVID para a continuación extrapolarlos a toda la población. Se intuye el sesgo de selección, ¿no? Es intuitivo pensar que la población que tiene un seguro de vida es de media más mayor que la que no lo tiene. De hecho, ¿cuánta gente joven conocéis que tenga seguro de vida? A falta de datos, es razonable pensar que extrapolar a toda la población ese dato es bastante engañoso. Varias personas en los comentarios han puntualizado este mismo razonamiento a Juanma, a lo que él responde (sin dar demasiada información) que "ese sesgo está recogido en la cifra de Mapfre". ¿Cuál de las dos cifras de Mapfre?
Esa operación nos entrega un resultado de 48144, que es la cifra que Juanma utiliza para decir que en España hay aproximadamente 50000 decesos por #COVID19. La pregunta inmediata es, ¿cómo de rigurosa es esa cifra y el método usado? Cualquier persona con mínimas nociones de estadística o matemáticas se habrá dado cuenta que este método hace aguas por todas partes. Una regla de tres a fin de cuentas no deja de ser una interpolación lineal, por tanto se corre el riesgo de que los resultados estén muy sesgados. Utilicemos un ejemplo muy sencillo. Imaginemos que en España un 5% de la población juega a la petanca. Imaginemos que entre los jugadores de petanca hay 5000 muertos por COVID. Según el método de Juanma, si entre el 5% de la población hay 5000 decesos en el 100% de la población habrá 5000x20=100000 decesos. Es evidente que este dato sería erróneo. La población que juega a la petanca suele ser de avanzada edad, por tanto la letalidad asociada al COVID será también mayor en ese grupo. Este error es un claro ejemplo de "sesgo de selección". Como soy nefasto explicando conceptos, dejo aquí este simpático vídeo donde se explica de una manera muy sencilla (a partir del minuto 4:30 aproximadamente, por Julio Basulto).Volviendo al método de Juanma, él parte de los casos de mortalidad notificados por Mapfre por COVID para a continuación extrapolarlos a toda la población. Se intuye el sesgo de selección, ¿no? Es intuitivo pensar que la población que tiene un seguro de vida es de media más mayor que la que no lo tiene. De hecho, ¿cuánta gente joven conocéis que tenga seguro de vida? A falta de datos, es razonable pensar que extrapolar a toda la población ese dato es bastante engañoso. Varias personas en los comentarios han puntualizado este mismo razonamiento a Juanma, a lo que él responde (sin dar demasiada información) que "ese sesgo está recogido en la cifra de Mapfre". ¿Cuál de las dos cifras de Mapfre?
 Parece evidente que no en la del número de decesos notificados por la compañía. No tiene ningún sentido normalizar un número de "muertes notificadas". Por tanto el único dato que nos queda es la "cuota de mercado".
Parece evidente que no en la del número de decesos notificados por la compañía. No tiene ningún sentido normalizar un número de "muertes notificadas". Por tanto el único dato que nos queda es la "cuota de mercado". Me parecería muy extraño que una cuota de mercado esté normalizada, de todos modos demos el beneficio de la duda y esperemos que @jmlopezzafra ponga algo más de luz en esto. En cualquier caso, aunque la cuota de mercado se encuentre normalizada, el cálculo seguiría siendo erróneo. ¿Por qué? Es algo más complicado de explicar en un tuit, y dependería de como se haya incluído el sesgo (si ha sido así) en la cifra que proporciona Juan Manuel. Si da más detalles de cómo se ha llegado a esa cifra estaré encantado de demostrarlo matemáticamente. En conclusión, esta información, que se ha demostrado del todo errónea, va ya por más de 300 retuits (entre ellos de cuentas de audiencias amplias como Luis del Pino), por lo que es de pensar que decenas de miles de personas lo han leído, muchas de ellas dándolo por válido. Y es que Juan Manuel López Zafra, el autor del "cálculo", es doctor en CCEE, profesor de Estadística y científico de datos. Por tanto, es de suponer que mucha gente que le sigue acepte lo que escribe por una suerte de falacia de autoridad.Conclusión: no os creáis todo lo que leéis, contrastad fuentes y, sobre todo, para asuntos relacionados con el COVID, buscad la opinión de expertos en epidemiología y sanitarios, no la de economistas y licenciados en empresariales. Plot twist: Juan Manuel ha leído el hilo y, como es evidente, no ha podido refutar ni una coma. Aún así ha dejado dos respuestas que servirán de cierre definitivo para este hilo. Obviemos los malos modales en la respuesta (cosas de la educación privada, imagino). Veamos:
Me parecería muy extraño que una cuota de mercado esté normalizada, de todos modos demos el beneficio de la duda y esperemos que @jmlopezzafra ponga algo más de luz en esto. En cualquier caso, aunque la cuota de mercado se encuentre normalizada, el cálculo seguiría siendo erróneo. ¿Por qué? Es algo más complicado de explicar en un tuit, y dependería de como se haya incluído el sesgo (si ha sido así) en la cifra que proporciona Juan Manuel. Si da más detalles de cómo se ha llegado a esa cifra estaré encantado de demostrarlo matemáticamente. En conclusión, esta información, que se ha demostrado del todo errónea, va ya por más de 300 retuits (entre ellos de cuentas de audiencias amplias como Luis del Pino), por lo que es de pensar que decenas de miles de personas lo han leído, muchas de ellas dándolo por válido. Y es que Juan Manuel López Zafra, el autor del "cálculo", es doctor en CCEE, profesor de Estadística y científico de datos. Por tanto, es de suponer que mucha gente que le sigue acepte lo que escribe por una suerte de falacia de autoridad.Conclusión: no os creáis todo lo que leéis, contrastad fuentes y, sobre todo, para asuntos relacionados con el COVID, buscad la opinión de expertos en epidemiología y sanitarios, no la de economistas y licenciados en empresariales. Plot twist: Juan Manuel ha leído el hilo y, como es evidente, no ha podido refutar ni una coma. Aún así ha dejado dos respuestas que servirán de cierre definitivo para este hilo. Obviemos los malos modales en la respuesta (cosas de la educación privada, imagino). Veamos:
 Juan Manuel invita a leer el informe de Mapfre. Honestamente me encantaría, pero no he dado con él, y Juan Manuel no parece querer compartirlo. Para finalizar, menciona en repetidas ocasiones que el "factor de elevación" justifica a su burda regla de tres. En cualquier caso, ya que Juan Manuel pone encima de la mesa el factor de elevación, hablemos del factor de elevación. ¿Qué es y para que se usa? Intentaré explicarlo. Imaginemos que hacemos una encuesta por teléfono para preguntar a la gente cualquier cosa. Por ejemplo, cuál es su color favorito y cuál es su edad. Imaginemos que hacemos muchas llamadas hasta alcanzar una muestra que consideremos representativa. Bien. Podríamos ordenar los datos y saber a qué % de la gente que hemos encuestado le gusta un color u otro. Como nuestra muestra es muy grande, un análisis ingenuo sería decir: "el color favorito de un 20% de los españoles es el azul". ¿Por qué esta afirmación sería ingenua? Porque estaríamos asumiendo que nuestra muestra es completamente similar al conjunto de los españoles. Es decir, que el % de gente entre 18-25 años (por ejemplo) en nuestra muestra (entre la gente que hemos llamado) es el mismo que el % de gente entre 18-25 años en el censo. ¿Es esto correcto? Probablemente no. Si hacemos llamadas telefónicas, probablemente habrá más respuesta de gente mayor (porque suelen pasar más tiempo en casa) y menos repuesta de gente en edad de trabajar (por el motivo contrario) y de gente muy joven (pues no van a responder). Por tanto, el resultado de nuestra encuesta no es directamente extrapolable a toda la población. Es decir, no se puede hacer una regla de tres para asumir cual es el color favorito de los españoles (lo siento @jmlopezzafra, tu herramienta favorita no sirve). Ahora bien, ¿hay alguna manera de corregir este error? Bueno, en nuestra encuesta hemos preguntado el color junto con la edad, ¿no? Entonces sabemos las franjas de edad de nuestra muestra. También sabemos las franjas de edad de la población española, consultando el censo. Se va intuyendo la solución, ¿no? Sabemos el "peso" que cada franja de edad tiene en nuestra muestra y en el total de los españoles. Es decir, podemos cuantificar si en nuestra muestra hay más o menos gente joven que la que en realidad hay en España, o si hay más o menos ancianos Es decir, si en nuestra encuesta hay un % más bajo de gente joven que la que realmente hay en España, la opinión de esa gente joven está "infrarrepresentada". Y al contrario, si nuestra muestra incluye un % mayor de gente anciana, su opinión estará "sobrerrepresentada". Bien, entonces parece obvio que los datos de nuestra encuesta hay que corregirlos para que cada franja de edad tenga el mismo "peso" y la misma representación que la que hay en el conjunto de la sociedad. ¿Cómo se hace esto? Efectivamente, con un factor de elevación. Aquí tenéis dos links por si queréis algo más de información de como se hacen estos cálculos. Concretamente estos dos ejemplos son de Encuestas de Población Activa, donde el uso de factores de elevación es muy habitual.ine.es/epa02/reponder…josamaga.webs.ull.es/jsmg-epa.pdf Ahora bien. ¿Justifica esto los cálculos de Juan Manuel? Evidentemente no. En primer lugar, él no utiliza en ningún momento factores de elevación. Repasad el hilo original, al que encuentre una sola mención a estos factores en sus cálculos le invito a una cena. En segundo lugar, si utilizara factores de elevación tendría que aplicarlos a la cifra de muertos por Covid proporcionada por Mapfre, para así poder extrapolarla al total de España y ser más riguroso. Cosa que no hace. Hace una regla de tres, que es totalmente lineal. La última baza que le queda al doctor Zafra es argüir que el 13.7% de cuota de mercado ya incluye ese factor de elevación. ¿Es esto posible? Respuesta corta: no. Con esto se cierra, espero que ya de forma definitiva, este hilo. No espero una respuesta del ínclito Juan Manuel, no creo que haya excusa que pueda usar para seguir justificando su bulo. Solo queda difundir la verdad, así que si has llegado hasta aquí, se aprecia difusión. Pequeña actualización. Como bien indica @juvenal_tw, en este artículo de @65ymuchomas se encuentra el dato que el sr Zafra utiliza en su análisis, la cuota de mercado de Mapfre (13,81%).https://www.65ymas.com/economia/empresas/santalucia-ocaso-mapfre-dominan-65-por-ciento-seguros-decesos_9748_102.htmlLa fuente original es el estudio "primas devengadas de seguro directo 2018", por @Inese_seguros data. El estudio no es open access y su precio es elevado, por tanto no lo podemos verificar.
Juan Manuel invita a leer el informe de Mapfre. Honestamente me encantaría, pero no he dado con él, y Juan Manuel no parece querer compartirlo. Para finalizar, menciona en repetidas ocasiones que el "factor de elevación" justifica a su burda regla de tres. En cualquier caso, ya que Juan Manuel pone encima de la mesa el factor de elevación, hablemos del factor de elevación. ¿Qué es y para que se usa? Intentaré explicarlo. Imaginemos que hacemos una encuesta por teléfono para preguntar a la gente cualquier cosa. Por ejemplo, cuál es su color favorito y cuál es su edad. Imaginemos que hacemos muchas llamadas hasta alcanzar una muestra que consideremos representativa. Bien. Podríamos ordenar los datos y saber a qué % de la gente que hemos encuestado le gusta un color u otro. Como nuestra muestra es muy grande, un análisis ingenuo sería decir: "el color favorito de un 20% de los españoles es el azul". ¿Por qué esta afirmación sería ingenua? Porque estaríamos asumiendo que nuestra muestra es completamente similar al conjunto de los españoles. Es decir, que el % de gente entre 18-25 años (por ejemplo) en nuestra muestra (entre la gente que hemos llamado) es el mismo que el % de gente entre 18-25 años en el censo. ¿Es esto correcto? Probablemente no. Si hacemos llamadas telefónicas, probablemente habrá más respuesta de gente mayor (porque suelen pasar más tiempo en casa) y menos repuesta de gente en edad de trabajar (por el motivo contrario) y de gente muy joven (pues no van a responder). Por tanto, el resultado de nuestra encuesta no es directamente extrapolable a toda la población. Es decir, no se puede hacer una regla de tres para asumir cual es el color favorito de los españoles (lo siento @jmlopezzafra, tu herramienta favorita no sirve). Ahora bien, ¿hay alguna manera de corregir este error? Bueno, en nuestra encuesta hemos preguntado el color junto con la edad, ¿no? Entonces sabemos las franjas de edad de nuestra muestra. También sabemos las franjas de edad de la población española, consultando el censo. Se va intuyendo la solución, ¿no? Sabemos el "peso" que cada franja de edad tiene en nuestra muestra y en el total de los españoles. Es decir, podemos cuantificar si en nuestra muestra hay más o menos gente joven que la que en realidad hay en España, o si hay más o menos ancianos Es decir, si en nuestra encuesta hay un % más bajo de gente joven que la que realmente hay en España, la opinión de esa gente joven está "infrarrepresentada". Y al contrario, si nuestra muestra incluye un % mayor de gente anciana, su opinión estará "sobrerrepresentada". Bien, entonces parece obvio que los datos de nuestra encuesta hay que corregirlos para que cada franja de edad tenga el mismo "peso" y la misma representación que la que hay en el conjunto de la sociedad. ¿Cómo se hace esto? Efectivamente, con un factor de elevación. Aquí tenéis dos links por si queréis algo más de información de como se hacen estos cálculos. Concretamente estos dos ejemplos son de Encuestas de Población Activa, donde el uso de factores de elevación es muy habitual.ine.es/epa02/reponder…josamaga.webs.ull.es/jsmg-epa.pdf Ahora bien. ¿Justifica esto los cálculos de Juan Manuel? Evidentemente no. En primer lugar, él no utiliza en ningún momento factores de elevación. Repasad el hilo original, al que encuentre una sola mención a estos factores en sus cálculos le invito a una cena. En segundo lugar, si utilizara factores de elevación tendría que aplicarlos a la cifra de muertos por Covid proporcionada por Mapfre, para así poder extrapolarla al total de España y ser más riguroso. Cosa que no hace. Hace una regla de tres, que es totalmente lineal. La última baza que le queda al doctor Zafra es argüir que el 13.7% de cuota de mercado ya incluye ese factor de elevación. ¿Es esto posible? Respuesta corta: no. Con esto se cierra, espero que ya de forma definitiva, este hilo. No espero una respuesta del ínclito Juan Manuel, no creo que haya excusa que pueda usar para seguir justificando su bulo. Solo queda difundir la verdad, así que si has llegado hasta aquí, se aprecia difusión. Pequeña actualización. Como bien indica @juvenal_tw, en este artículo de @65ymuchomas se encuentra el dato que el sr Zafra utiliza en su análisis, la cuota de mercado de Mapfre (13,81%).https://www.65ymas.com/economia/empresas/santalucia-ocaso-mapfre-dominan-65-por-ciento-seguros-decesos_9748_102.htmlLa fuente original es el estudio "primas devengadas de seguro directo 2018", por @Inese_seguros data. El estudio no es open access y su precio es elevado, por tanto no lo podemos verificar. Sin embargo, por lo que se deduce del artículo de @65ymuchomas, la cuota de mercado no tiene ningún tipo de corrección, como era obvio. Es más, la cuota de cada aseguradora está calculada sobre el total del volumen de primas, no respecto al total del volumen de clientes. Es decir, la simple regla de tres de Juan Manuel tiene aún menos sentido ya que está asumiendo que la cuota calculada respecto al volumen de primas es igual a la que resultaría si se calculara respecto al volumen de clientes, lo que no tiene por qué ser verdad. Otro error más. Ahora sí, a falta de respuesta de Juan Manuel, damos por cerrado el artículo. FIN.Y ante la falta de argumentos... una pena.
Sin embargo, por lo que se deduce del artículo de @65ymuchomas, la cuota de mercado no tiene ningún tipo de corrección, como era obvio. Es más, la cuota de cada aseguradora está calculada sobre el total del volumen de primas, no respecto al total del volumen de clientes. Es decir, la simple regla de tres de Juan Manuel tiene aún menos sentido ya que está asumiendo que la cuota calculada respecto al volumen de primas es igual a la que resultaría si se calculara respecto al volumen de clientes, lo que no tiene por qué ser verdad. Otro error más. Ahora sí, a falta de respuesta de Juan Manuel, damos por cerrado el artículo. FIN.Y ante la falta de argumentos... una pena.
#6 Gracias por la aclaración.
#9 Gracias por el enlace. Paciencia, llevo dos días registrado en la plataforma. No pretendo compartir únicamente mi contenido. Saludos.
#2 ¿Dónde está el Spam? De verdad que no lo entiendo. Estoy compartiendo la fuente externa (Twitter) y adicionalmente ordenando los hilos de Twitter en forma de artículo para quien le sea más cómodo leerlo así. ¿Dónde está el spam ahí? ¿Sabes lo cansino que es pasar un hilo de Twitter a formato artículo?
#5 ¿Dónde está el Spam? De verdad que no lo entiendo. Estoy compartiendo la fuente externa (Twitter) y adicionalmente ordenando los hilos de Twitter en forma de artículo para quien le sea más cómodo leerlo así. ¿Dónde está el spam ahí? ¿Sabes lo cansino que es pasar un hilo de Twitter a formato artículo?
#9 Gracias por el enlace. Paciencia, llevo dos días registrado en la plataforma. No pretendo compartir únicamente mi contenido. Saludos.
#3 Gracias, no estaba al tanto.
Juan Manuel López Zafra es Doctor en Ciencias Empresariales y se autodenomina experto en Estadística y Big Data. Recientemente ha aumentado su popularidad en RRSS, especialmente en Twitter, haciendo análisis utilizando datos de muertes por Coronavirus. En muchos de ellos comete errores flagrantes, impropios de una persona con conocimientos básicos de Estadística. Muchos de estos resultados han sido publicados en Vozpópuli, demostrando una vez más falta de rigor habitual en la prensa generalista.
#3 Desconozco lo de los "papeles de la vergüenza". En mi hilo únicamente analizo un análisis de datos deliberadamente falso y manipulado.
#3 ¿Puedes decirme cuáles? A mi se me ven bien desde dos dispositivos diferentes...

#4 Si le doy a abrir la imagen en otra ventana las veo bien... pero no me aparecen integradas en el texto de tu artículo. A partir de la tercera imagen.
#1 ¿Cuáles? ¿Las imágenes?
La empresa de Big Data "Dathos", con cierta presencia en redes a raíz de diferentes análisis sobre violencia de género, inmigración y, ahora, coronavirus, ha publicado en reiteradas ocasiones análisis de datos en Twitter con métodos claramente erróneos con la única intención de manipular y reforzar un discurso preestablecido. En este estudio sus mentiras quedan al desnudo.
Nota: este artículo proviene de Twitter. Se agradece difusión. https://twitter.com/Martinez__Rafa/status/1262405189388156930?s=20Recientemente he encontrado otro ejemplo de manipulación deliberada. Como, pasados unos días, los autores se niegan a rectificar, procedo a escribir este artículo. La manipulación, en este caso, proviene de @DathosBD. Dathos es una asociación del sector de Big Data, Algorithms & Risk Analysis, como ellos mismos se definen (dathorizon.com). Por lo que se intuye de su perfil de Twitter y de su página web son expertos en Estadística y análisis de datos. Bien, @DathosBD lleva un tiempo haciendo simulaciones y modelos para estimar el número de fallecidos por #COVID19. Recientemente, han comenzado a utilizar los datos del informe MoMo de mortalidad para "verificar" los datos de sus simulaciones. Aquí hacen un análisis similar, con el mismo modus operandi pero con datos actualizados a otra fecha.
Aquí hacen un análisis similar, con el mismo modus operandi pero con datos actualizados a otra fecha. Bien, vayamos al grano. Verifiquemos el primero de sus análisis(7 de Mayo). Las conclusiones que saquemos para este son válidas para el resto de análisis que @DathosBD ha publicado usando datos MoMo, pues en todos hace las mismas suposiciones (por ejemplo, el del 12 de Mayo).
Bien, vayamos al grano. Verifiquemos el primero de sus análisis(7 de Mayo). Las conclusiones que saquemos para este son válidas para el resto de análisis que @DathosBD ha publicado usando datos MoMo, pues en todos hace las mismas suposiciones (por ejemplo, el del 12 de Mayo). Bien. La hipótesis del hilo es que, a 5 de Mayo, en España habrían muerto 45.000 personas por #COVID19. Según @DathosBD, esta cifra se deduce del informe de mortalidad MoMo analizando los datos nacionales y autonómicos, y refuerza sus simulaciones. Dathos parte de los datos del informe MoMo desde el 17 de Marzo al 2 de Mayo, donde se presenta una cifra observada de 82409 fallecidos. La cifra de defunciones estimadas es de 51703, por lo que en ese período hay un exceso de fallecimientos respecto al esperado de 30706 (59%)
Bien. La hipótesis del hilo es que, a 5 de Mayo, en España habrían muerto 45.000 personas por #COVID19. Según @DathosBD, esta cifra se deduce del informe de mortalidad MoMo analizando los datos nacionales y autonómicos, y refuerza sus simulaciones. Dathos parte de los datos del informe MoMo desde el 17 de Marzo al 2 de Mayo, donde se presenta una cifra observada de 82409 fallecidos. La cifra de defunciones estimadas es de 51703, por lo que en ese período hay un exceso de fallecimientos respecto al esperado de 30706 (59%) Continuemos. @DathosBD añade más datos a la ecuación, aunque esta vez sin indicar claramente la fuente. Indican que, haciendo el mismo recuento por CCAA, los datos totales son 37345 fallecidos estimados, y 68253 fallecidos observados.
Continuemos. @DathosBD añade más datos a la ecuación, aunque esta vez sin indicar claramente la fuente. Indican que, haciendo el mismo recuento por CCAA, los datos totales son 37345 fallecidos estimados, y 68253 fallecidos observados. Pues bien, estos son todos los datos que @DathosBD utiliza para su análisis. La pregunta es, ¿cómo con 4 datos tan simples y que, además, son inconsistentes (la suma de las CCAA debería ser igual al total nacional) se puede hacer una estimación de las muertes por #COVID19? Bien, el método que @DathosBD utiliza, que es erróneo, es restar al valor observado más alto (el nacional, 82409) el valor estimado más bajo (la suma de los regionales, 37345). Esta diferencia es 45064 fallecidos. ¿Alguna explicación de por qué se eligen esos valores? No.
Pues bien, estos son todos los datos que @DathosBD utiliza para su análisis. La pregunta es, ¿cómo con 4 datos tan simples y que, además, son inconsistentes (la suma de las CCAA debería ser igual al total nacional) se puede hacer una estimación de las muertes por #COVID19? Bien, el método que @DathosBD utiliza, que es erróneo, es restar al valor observado más alto (el nacional, 82409) el valor estimado más bajo (la suma de los regionales, 37345). Esta diferencia es 45064 fallecidos. ¿Alguna explicación de por qué se eligen esos valores? No. Creo que no hay que dar demasiadas explicaciones de por qué escoger valores de manera arbitraria y sin justificar es una práctica incorrecta. Un ejemplo muy sencillo, el mismo cálculo podría hacerse escogiendo el valor observado más bajo (68253) y el estimado más alto (51703). Esto entregaría una cifra de fallecidos 16550, lo cual es absurdo, ya que esta cifra sería incluso inferior al número de fallecidos notificados por @sanidadgob en aquellas fechas. Aún así, asumamos que la hipótesis de @DathosBD es correcta, y es riguroso utilizar justo esos datos ¿Es correcta entonces la estimación y las conclusiones de @DathosBD ? Rotundamente no. Lo explico. ¿Recordáis que la suma de los datos de cada CCAA no coincidía con el total entregado por MoMo a nivel nacional? Resulta extraño teniendo en cuenta que ambos datos son de MoMo, ¿no? Bien, la explicación es sencilla. Los periodos de ambos datos (los de cada CCAA y los nacionales) son diferentes. Mientras que el dato de España cubre todo el período analizado, los de cada región son diversos. En la tabla adjunta (via @elespanolcom) se observa esta discrepancia.
Creo que no hay que dar demasiadas explicaciones de por qué escoger valores de manera arbitraria y sin justificar es una práctica incorrecta. Un ejemplo muy sencillo, el mismo cálculo podría hacerse escogiendo el valor observado más bajo (68253) y el estimado más alto (51703). Esto entregaría una cifra de fallecidos 16550, lo cual es absurdo, ya que esta cifra sería incluso inferior al número de fallecidos notificados por @sanidadgob en aquellas fechas. Aún así, asumamos que la hipótesis de @DathosBD es correcta, y es riguroso utilizar justo esos datos ¿Es correcta entonces la estimación y las conclusiones de @DathosBD ? Rotundamente no. Lo explico. ¿Recordáis que la suma de los datos de cada CCAA no coincidía con el total entregado por MoMo a nivel nacional? Resulta extraño teniendo en cuenta que ambos datos son de MoMo, ¿no? Bien, la explicación es sencilla. Los periodos de ambos datos (los de cada CCAA y los nacionales) son diferentes. Mientras que el dato de España cubre todo el período analizado, los de cada región son diversos. En la tabla adjunta (via @elespanolcom) se observa esta discrepancia. Es decir, combinan datos a escala nacional y a escala autonómica, cuando cubren periodos totalmente diferentes, lo cual es evidentemente incorrecto desde un punto de vista estadístico. @DathosBD hace trampas al solitario e intenta manipular datos para reforzar sus estimaciones. Con esto cierro. Me resulta increíble como supuestos expertos, con presencia en medios y audiencias amplias son capaces de manipular tan abiertamente. Y digo manipular, porque cualquier persona con conocimientos mínimos de análisis de datos es capaz de ver estos errores a leguas.
Es decir, combinan datos a escala nacional y a escala autonómica, cuando cubren periodos totalmente diferentes, lo cual es evidentemente incorrecto desde un punto de vista estadístico. @DathosBD hace trampas al solitario e intenta manipular datos para reforzar sus estimaciones. Con esto cierro. Me resulta increíble como supuestos expertos, con presencia en medios y audiencias amplias son capaces de manipular tan abiertamente. Y digo manipular, porque cualquier persona con conocimientos mínimos de análisis de datos es capaz de ver estos errores a leguas.
#15 Si todo el mundo supiera como es quiero creer que no sería uno de las figuras más relevantes del principal partido de la oposición.
Este artículo fue inicialmente publicado en Twitter en forma de hilo. Se agradece difusión. twitter.com/Martinez__Rafa/status/1266675559284826112?s=20.Este breve artículo pretende hacer un análisis de la actividad en Twitter en el mes de mayo de Rafael Hernando (@Rafa_Hernando), senador y hombre fuerte del PP.Ha publicado, hasta el momento, 157 tuits.🔹133 de esos tuits (85%) son críticas al Gobierno.🔹Ha escrito "dr. Fraude" 23 veces.🔹Ha escrito "Coletas" 8 veces. 🔹Ha hablado de "socialcomunismo" en 14 ocasiones.🔹Venezuela o similares: 7 veces.🔹"Podemita": 4.🔸Menciones al PP, o a medidas tomadas por el PP: 9.En este mismo período, el sr. Hernando ha publicado 38 tuits con material multimedia.🔹32 (85%) son críticas multimedia al Gobierno.🔹Solo 2 relacionadas con el PP. Es decir, la actividad en redes del sr. Hernando se basa únicamente en la crítica (en muchas ocasiones maleducada) al Gobierno. La difusión de propuestas o críticas constructivas es marginal.¿Funciona esta estrategia? Mucho. Hernando ha ganado aprox. 3500 seguidores este mes. El impacto en seguidores e impacto en esta crisis sanitaria por parte de @Rafa_Hernando es el mayor desde que tenemos registros disponibles en @SocialBlade. Únicamente con la moción de censura (mayo, junio 2018) encontramos picos similares.
El impacto en seguidores e impacto en esta crisis sanitaria por parte de @Rafa_Hernando es el mayor desde que tenemos registros disponibles en @SocialBlade. Únicamente con la moción de censura (mayo, junio 2018) encontramos picos similares. Hasta aquí los datos. Mi opinión: es vergonzoso que un político de primera línea de la oposición (recordemos, secretario tercero del Senado, exportavoz del grupo popular en el Congreso y hombre fuerte de Rajoy) utilice reiteradamente términos como "Dr. Fraude" o "Coleta". Es nuestro deber como ciudadanos exigir que los políticos se comporten como lo que son, representantes de la ciudadanía, y no como tertulianos de barra de bar o como cuñaos en una cena de Nochebuena.
Hasta aquí los datos. Mi opinión: es vergonzoso que un político de primera línea de la oposición (recordemos, secretario tercero del Senado, exportavoz del grupo popular en el Congreso y hombre fuerte de Rajoy) utilice reiteradamente términos como "Dr. Fraude" o "Coleta". Es nuestro deber como ciudadanos exigir que los políticos se comporten como lo que son, representantes de la ciudadanía, y no como tertulianos de barra de bar o como cuñaos en una cena de Nochebuena.
#11 Es sintomático que el 90% de lo que escribe sean "críticas", y lo entrecomillo porque la palabra más acertada sería insultos.
#10 Cierto. Buenos mentores para Hernando.
#5 Exacto, qué mala es la hemeroteca.
Juan Manuel López Zafra es Doctor en Ciencias Empresariales y se autodenomina experto en Estadística y Big Data. Recientemente ha aumentado su popularidad en RRSS, especialmente en Twitter, haciendo análisis utilizando datos de muertes por Coronavirus. En muchos de ellos comete errores flagrantes, impropios de una persona con conocimientos básicos de Estadística. Muchos de estos resultados han sido publicados en Vozpópuli, demostrando una vez más falta de rigor habitual en la prensa generalista.
La empresa de Big Data "Dathos", con cierta presencia en redes a raíz de diferentes análisis sobre violencia de género, inmigración y, ahora, coronavirus, ha publicado en reiteradas ocasiones análisis de datos en Twitter con métodos claramente erróneos con la única intención de manipular y reforzar un discurso preestablecido. En este estudio sus mentiras quedan al desnudo.
El senador y exdiputado del PP, Rafael Hernando, tiende a utilizar las redes sociales, en especial Twitter, de una manera muy agresiva rozando en ocasiones la mala educación. En este hilo de Twitter se analizan algunas métricas del citado Hernando en el mes de mayo.
#36 Bueno, que la cifra real está entre 40.000 y 50.000 parece evidente teniendo en cuenta los datos disponibles. El problema es que Juan Manuel parte de la cifra a la que quiere llegar y a partir de ahí fabrica un método para justificarla. Eso es muy grave, porque disfraza de ciencia lo que no es más que una manipulación.
#11 Hola. Muchas gracias, la verdad es que aún ando trasteando con la web, se agradece el consejo.
Esta sección es la de artículos, cierto? Entonces publicar los artículos aquí y enlazarlos directamente no sería considerado spam? Gracias por la ayuda!
#28 Hay una web que te hace el trabajo de poner un hilo de twitter más legible, te paso un ejemplo con uno de tus hilos:
https://threadreaderapp.com/thread/1259472794817048577.html
https://threadreaderapp.com/
#28 Exacto. Puedes combinar ambas cosas y hacer un envío "todo en uno" si no te importa el trabajo extra: el artículo completo más el enlace al tuit donde lo publicas, siempre que tú seas el autor.
También puedes publicar en tu Twitter el enlace al artículo en Menéame, para quien prefiera otra método de lectura del artículo.
#37 Gracias!
#9 Hola. La cifra final a la que llega es un claro de ejemplo de fabricación de datos, ya que parte de la hipótesis final y crea el método (muy chapucero, indigno para un doctor usar reglas de tres) para llegar a ese resultado. Esto es un ejemplo perfecto de manipulación y falseamiento de datos.
#21 Ya te he respondido educadamente, pero veo que continúas insistiendo así que lo repito.
He publicado el hilo como enlace y como artículo A LA VEZ, con el esfuerzo que ello conlleva, para dar más facilidades a quien prefiera formato Twitter o formato artículo. No escribo el artículo porque el enlace no tenga "éxito" (no sé a qué te refieres), lo hago A LA VEZ.
#5 Con el agravante de ser profesor de Universidad en la materia y "experto". Cero rigor.
#6 Hola, soy nuevo aquí y quizá desconozco algunas de las reglas internas de la web, disculpas por ello.
He publicado en dos formatos (enlace y artículo) no por duplicar, sino porque entiendo que para algunas personas quizá es más cómodo no salir de la Web y leerlo directamente aquí. Para mí es más cómodo pegar el enlace, adaptarlo al formato artículo es bastante time consuming.
Respecto a lo del texto original, tal como leí en las condiciones de la Web no hay problema con tal de que las contribuciones no queden reducidas únicamente a autopublicidad, es decir, si también comparto noticias de otras fuentes no hay problemas, siempre según los términos y condiciones de Menéame.
No entiendo lo de "como no tiene éxito". Hice los dos formatos a la vez, me importa bien poco el "éxito", solo quiero dar a conocer una mala práctica.
Un saludo.
#23 El artículo está bien... ya estaba publicado en otro artículo en portada: Desmontando las cifras de muertos por covid-19 de un experto en Big Data
El autobombo está permitido de forma ocasional. Tú no has subido nada que no sean tus tweets... es spam.
Cuando digo tener éxito me refiero a llegar a portada. No puedes enviar lo mismo en articulos que en historias... es duplicada.
#6 Gracias por la aclaración.
#9 Gracias por el enlace. Paciencia, llevo dos días registrado en la plataforma. No pretendo compartir únicamente mi contenido. Saludos.
#2 ¿Dónde está el Spam? De verdad que no lo entiendo. Estoy compartiendo la fuente externa (Twitter) y adicionalmente ordenando los hilos de Twitter en forma de artículo para quien le sea más cómodo leerlo así. ¿Dónde está el spam ahí? ¿Sabes lo cansino que es pasar un hilo de Twitter a formato artículo?
#5 ¿Dónde está el Spam? De verdad que no lo entiendo. Estoy compartiendo la fuente externa (Twitter) y adicionalmente ordenando los hilos de Twitter en forma de artículo para quien le sea más cómodo leerlo así. ¿Dónde está el spam ahí? ¿Sabes lo cansino que es pasar un hilo de Twitter a formato artículo?
#9 Gracias por el enlace. Paciencia, llevo dos días registrado en la plataforma. No pretendo compartir únicamente mi contenido. Saludos.
#3 Gracias, no estaba al tanto.
#3 Desconozco lo de los "papeles de la vergüenza". En mi hilo únicamente analizo un análisis de datos deliberadamente falso y manipulado.
#3 ¿Puedes decirme cuáles? A mi se me ven bien desde dos dispositivos diferentes...
#4 Si le doy a abrir la imagen en otra ventana las veo bien... pero no me aparecen integradas en el texto de tu artículo. A partir de la tercera imagen.
#1 ¿Cuáles? ¿Las imágenes?
#15 Si todo el mundo supiera como es quiero creer que no sería uno de las figuras más relevantes del principal partido de la oposición.
#11 Es sintomático que el 90% de lo que escribe sean "críticas", y lo entrecomillo porque la palabra más acertada sería insultos.
#10 Cierto. Buenos mentores para Hernando.
#5 Exacto, qué mala es la hemeroteca.
#36 Bueno, que la cifra real está entre 40.000 y 50.000 parece evidente teniendo en cuenta los datos disponibles. El problema es que Juan Manuel parte de la cifra a la que quiere llegar y a partir de ahí fabrica un método para justificarla. Eso es muy grave, porque disfraza de ciencia lo que no es más que una manipulación.